We’re getting our hands dirty with OpenRefine – one of The Outlier’s favourite tools when working with large datasets. This powerful open-source program is ideal for cleaning messy data.
In this post, we’re focusing on two essential features of OpenRefine: removing duplicates and using version history to keep track of your changes. First, though, we need to explain faceting, a powerful feature of OpenRefine.
Watch the video
What is faceting?
Faceted browsing allows you to explore and filter data dynamically. You can navigate large datasets by applying filters and performing operations on specific subsets. It works by categorising values in a specific column, making it easier to identify patterns or spot inconsistencies across large datasets.
For example, a facet can display the distribution of values in a column, like the number of entries by year in a date column or the frequency of different text values. This grouping can quickly reveal trends or highlight errors in your data.
Navigating menus
OpenRefine displays your dataset in a grid-like view, similar to Excel or Google Sheets, with column headings at the top and rows of data beneath them. You’ll also notice a downward arrow next to each column heading. Clicking on these accesses the options for manipulating your data.
Removing duplicates
Duplicate entries can skew your data for obvious reasons. Here’s how to get rid of them:
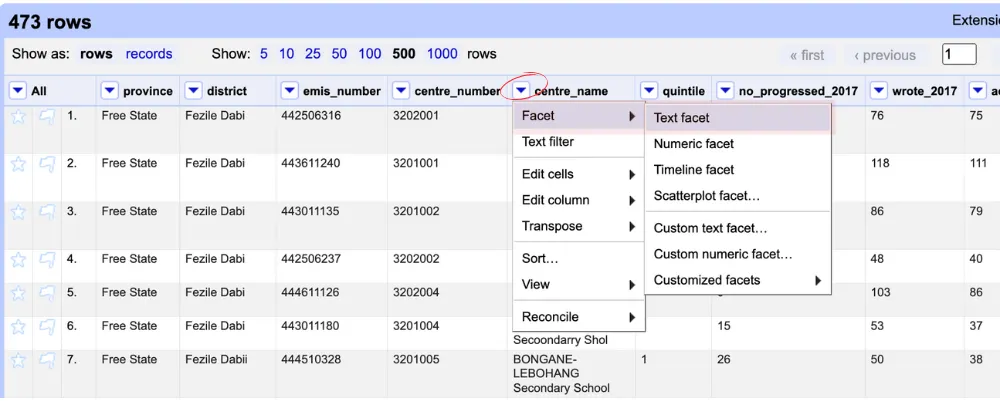
1. Click the downward arrow under the column where you suspect duplicates might exist.
2. From the dropdown menu, select Facet, then choose Customized facets and click on Duplicates facet. OpenRefine will display two options: True (for rows with duplicates) and False (for rows without duplicates). The numbers next to each option show how many rows are duplicates and how many are unique.
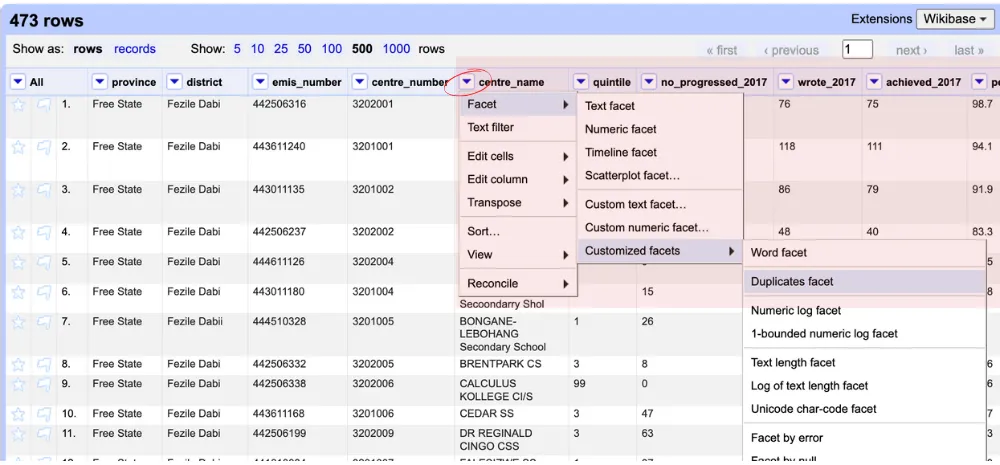
3. Click on True to view the rows with duplicate entries. (This includes the singles you want to keep as well as any duplicates.)
4. Once you’ve identified the duplicates, mark the rows you wish to remove by using the star feature.
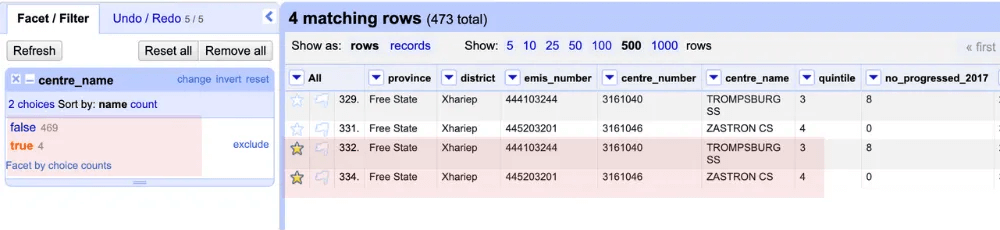
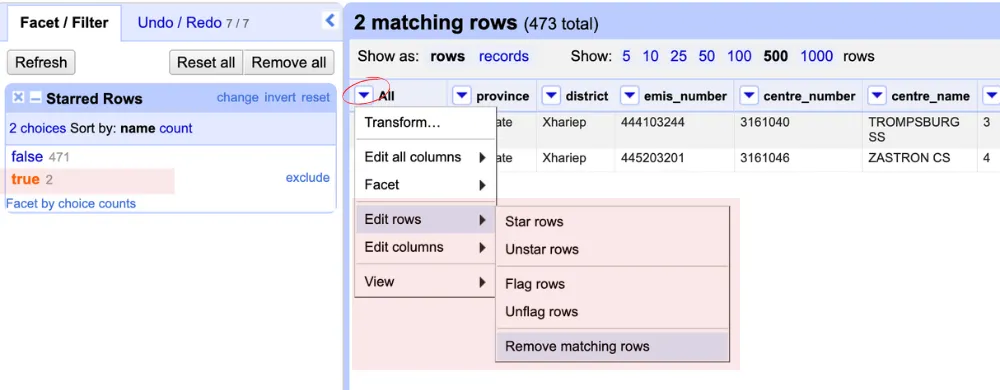
5. To remove the duplicates, exit the facet view and click on the dropdown arrow next to All. Choose Facet, then select Facet by star.
6. OpenRefine will display the rows you’ve starred. You can now delete the duplicates by selecting Edit rows from the dropdown, then clicking Remove matching rows. With that, your duplicates are gone!
Pro tip: Keep track by keeping an eye on the number of total rows, displayed in brackets in the top strip.
Renaming columns
You may want to rename columns to make your data clearer or more meaningful. Here’s how to do that:
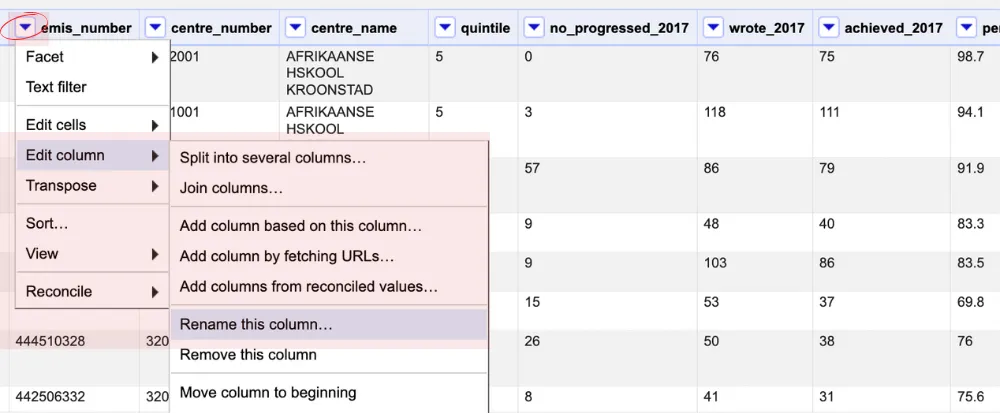
- Click the downward arrow next to the column you want to rename.
- Choose Edit columns, then select Rename this column. Enter the new name for the column that makes it easy to understand.
- Repeat this process for other columns as well to ensure consistency and clarity throughout your dataset.
Version history: Track your changes
One of OpenRefine’s most valuable features is its version history. This feature helps you track all the changes you’ve made and allows you to easily undo or redo any steps if needed.
Here’s how to access it:
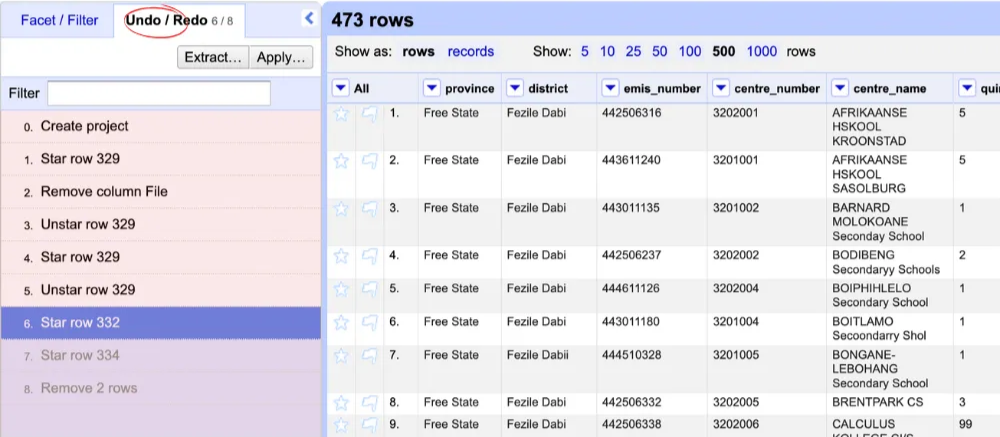
- In the top left-hand corner, click on the Undo/Redo tab.
- A list of all the changes you’ve made will appear, showing every action taken in your OpenRefine project.
- If you need to undo a change, simply click on the specific action in the list, and OpenRefine will revert to that previous version of your data.
This makes it easy to experiment with your dataset without worrying about losing your original data or previous steps.
The full series
Part 1: Installing OpenRefine and merging datasets | WATCH
Part 2: Removing duplicates and tracking changes | WATCH
Part 3: Fixing inconsistencies with the cluster and edit tool | WATCH
Notebook
- OpenRefine’s official website and documentation
- Read more: 5 reasons to switch to OpenRefine to clean data
- Subscribe to The Outlier’s YouTube channel to be notified of new updates
- Sign up to The Outlier’s newsletter for weekly tools, tips and data-driven insights